This article talks about CRM Debugging and BOL Programming and...
Read MoreThis blog talks about how to use the master data extraction program in master data extraction program to read data from ECC to Ariba system. This blog talks about below topic areas:
The standard program /ARBA/MASTER_DATA_EXPORT needs customization or you will keep wasting your time to find the implicit enhancement points which are too less and not in the right places. So I just did what was the easier thing to do copied the entire program as a Z and then did the changes. When you run the program you see radio buttons like Procure to Order and Procure to Pay, Sourcing, and contracts.
What needs to run depends on what modules you implement in Ariba. A lot of the contents available to download is common among sourcing and P2P and P2O radio buttons. However it still needs to run twice as it updates specific modules in Ariba. So based on what you select you get options to ‘Choose Master data to export’ you get different master data options.
To understand better you need to first extract company code from P2O and then extract company code again from sourcing. So even though it is the identical company code master data will get export. But it needs to go to different modules in Ariba like sourcing and contract management so you need to run the extractors twice. Generally procurement scenario in Ariba consist of
P2P: Contracts Orders and Invoicing
P2O: Contracts only
You can also choose to send data as an initial load one time and as an incremental load. So you would need to run :
There are also connectivity options like :

It is advisable to follow a specific logic to ensure the correct data. And in the right sequence, uploaded to the Ariba system. It is advisable to fill Sourcing and contracts before as its an Upstream module in Ariba and the others are downstream
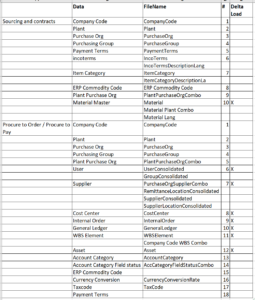
There may be a need for some customization to either clean/correct the data which is send to Ariba. I am specifying some of the scenarios below:
To Change column Name or add an additional column and populate data:
It may require you to change some column name to make it as the primary key. For example instead of the user Id which is the default primary key for the user extraction client wants to make email ID as the primary key. So, I had to change the name of the column for email as UNIQUENAME (Ariba understand UniqueName column as the primary key) for the user extraction file and assign it as value of email. In /ARBA/FIELD_MAP the field BNAME (User ID) currently is mapped to Ariba field UNIQUENAME. I now want the email ID field to populate for UniqueName.


Also I changed the label for BNAME to UserId as only 1 field can have value as UniqueName which becomes the key in Ariba .


3. To assign a value to this column we need to change code to read email of the user:
And in order to add value to this field I used BADI /ARBA/MASTER_DATA. This badi has all the user extraction data methods as seen below

Method /ARBA/IF_EXP_MASTER_DATA~MODIFY_USER_DATA is called for each time the user record is extracted so I enter my field UNIQUENAME1 and pass Email address. Remember, this is a structure, so we will call it for all entries one by one.

However most of the methods like /ARBA/IF_EXP_MASTER_DATA~PUBLISH_USER_DATA have exporting /changing parameter as table. So you can loop at each record and delete if the Email ID is blank etc as this is our primary key so keeping it blank will create issues in Ariba. 
Now when you have the file extracted as a CSV it will have an additional column as UniqueName with the email ID of the user when the Ariba program will run.

Note that not all data can be set up as incremental load. In P2O/P2P scenario the incremental load consists of below master data.

In Sourcing and contracts below master data can schedule to run for incremental data:

If the data which you wish the send to Ariba is not included in the incremental list above like product category, Pur grp, company code, pur org etc. then you need to either update that manually or send an initial load everytime as needed.
How would the system know what changes occured since last time and how to pick the delta load?
he program handles the incremental load based on a table /ARBA/INCR_DTTIM. Everytime an incremental load is run the table gets updated with date and time of the specific load which was run. THe next time system would automatically filter the data based on the last updated fill from the table for users, suppliers or other master data for which you plan to run the incremental load. After the load run the system automatically update the Date information and the next time for incremental load it references this to understand what has been the delta change in the system since the last run.
:
To ensure the data is sent to the right destination /ARBA/auth_param table should be populated. Ensure you have maintained the necessary parameters in the table /ARBA/ AUTH_PARAM so the ECC system points to the correct Ariba Realm

/ARBA/IF_EXP_MASTER_DATA~PUBLISH_SUPPLIER_INCREMENT
For incremental load for users SAP does not provide any method in the BADI to modify the incremental load files for deletion like userdelete and usergroupdelete files.
These files, User Delete File and UserGroup delete file, are send to Ariba to deactivate those users who have left the organisation. However no method in the BADI is for formatting these files. Hence I came up with a workaround as below. Overwrite the extracted user deletion and group_deletion file with the required data.
Note that in the deletion file only one column is updated the primary key using which Ariba system would know which user to deactivate.Since I had changed the primary key to email this was not populated in the deletion files being sent to Ariba and system would not know which user to deactivate. So I did below
Rename the file using below code where gv_fname is the file that you generate without the filter. So I am Overwriting the same extracted file with additional information that I need to pass to the Ariba system. In my master data program, I modify the gr_user_del file to add email and also rename the file to the same name by Ariba so my file will replace the original file which you create by the program.
*** Modify the deleted file as needed:
IF sy-subrc EQ 0. "update entry with email
ls_user_del-uniquename1 = ls_smtp-e_mail.
MODIFY gt_user_del FROM ls_user_del INDEX lv_index.
ENDIF.
***** overwrite the file
CONCATENATE gv_fname 'GroupConsolidated_Delete.csv' INTO lv_file_name.
CALL FUNCTION '/ARBA/DATA_CONVERT_WRITE_FILE'
EXPORTING
i_filename = lv_file_name
i_fileformat = 'CSV'
i_field_seperator = ','
i_tabname = '/ARBA/USER'
i_encoding = 'UTF-8'
i_solution = 'AR'
TABLES
i_tab_sender = gt_user_del
EXCEPTIONS
open_failed = 1
close_failed = 2
write_failed = 4
conversion_failed = 5
OTHERS = 6.
IF sy-subrc <> 0. "#EC NEEDED
ENDIF.
Thanks for reading. I hope this document is helpful for those looking to find some help on using the master data extraction program.
For more information and services:https://peritossolutions.com/services/sap-consulting-services
This article talks about CRM Debugging and BOL Programming and...
Read More
This blog explains how to Control CRM UI elements to...
Read More
Understand how to create SAP Custom Search help and Understand...
Read More